大多数 Obsidian 工作流的问题,不在于记不住,而在于知识不会持续重组。
你可以剪藏文章、整理目录、打标签、做双链,甚至维护一套看起来很漂亮的 vault。可一旦输入规模上来,系统很快就会退化成一个静态仓库。新材料进来了,旧判断不会自动更新;相关主题之间没有稳定的重组机制;问答阶段产生的新洞见,最后也常常留在聊天记录里,没法回到知识库本身。
LLM Brain 就是我为这个问题做的一层知识编译系统。
它不是一个单纯的笔记插件,也不是一个把文档喂给 LLM 再做问答的轻量封装。更准确地说,它是一条运行在 Obsidian 文件结构之上的编译链路。输入是 raw/ 目录下的原始材料,输出是一个持续演化的 wiki,包括结构化摘要、概念卡、公司档案、人物档案、索引页,以及后续问答回写形成的分析卡片。
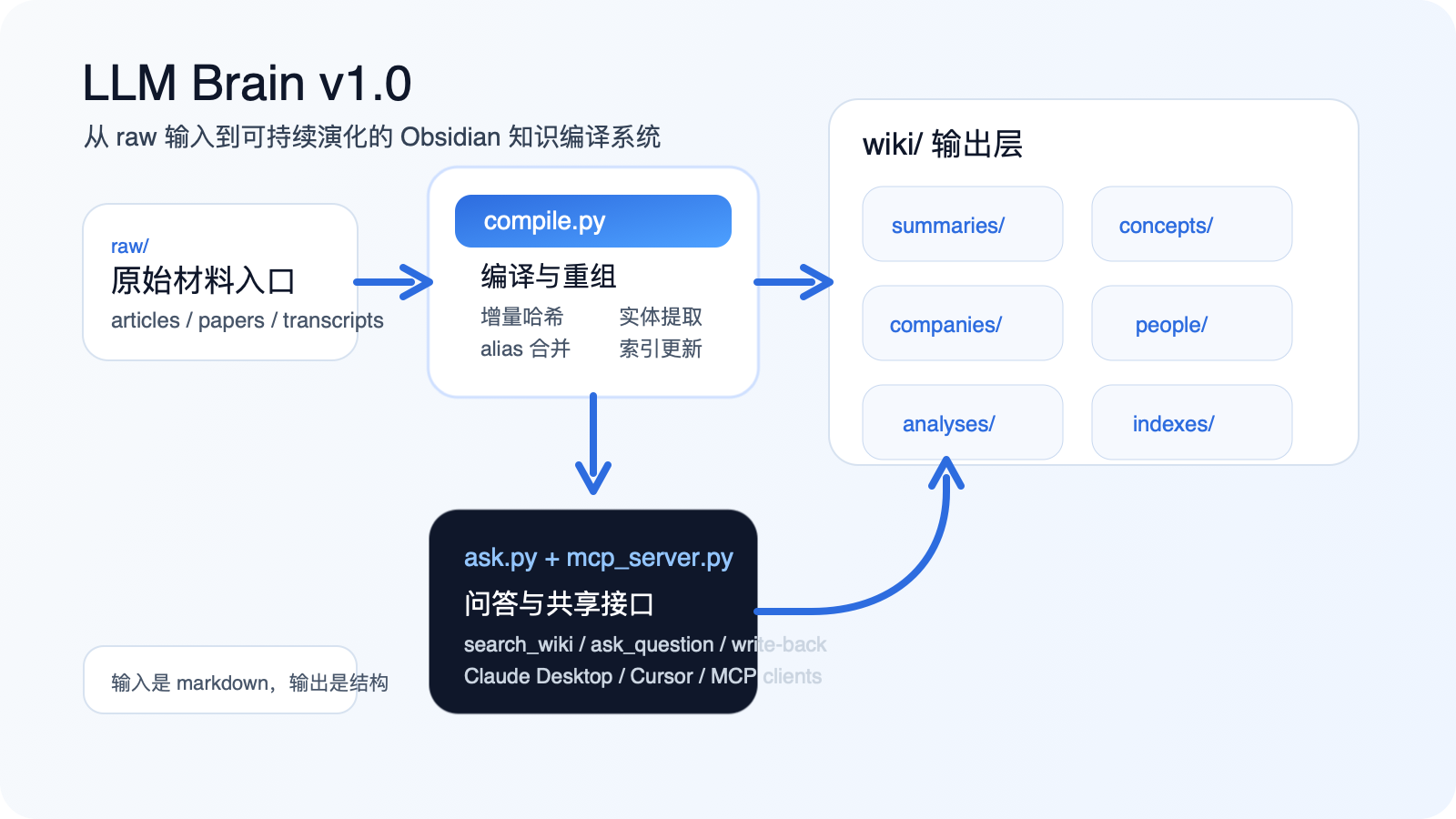
raw/ 输入,到 compile.py 编译,再到 wiki/ 输出与 ask.py + mcp_server.py 的共享接口。项目地址:https://github.com/ylouis83/llm-brain
这篇文章里我想讲清楚三件事,它借鉴了什么,它具体怎么工作,以及为什么我觉得这种系统比“再做一个 AI 笔记功能”更值得继续做下去。
这套思路并不是凭空冒出来的
LLM Brain 最直接的上游来源,是 Andrej Karpathy 在 LLM Wiki 里提出的那套模式。
Karpathy 的核心判断非常准确,与其在提问时一遍遍从原始文档里做检索,不如让 LLM 先把材料持续编译成一个持久化 wiki。原始来源放在 raw/,LLM 维护 wiki/,再通过 schema 约束整个工作流。这样知识不是每次问答时临时拼出来的,而是被提前整理、持续更新、不断积累的。
LLM Brain 基本接受了这条主线,但我没有停在“模式说明”这一层,而是把它进一步压成一套本地可运行的文件系统工作流。
另一个明确影响我的是 MindOS。它最打动我的地方,不是 UI,而是它把“共享知识层”讲得很彻底。知识库一旦能被多个 Agent 共同读写,系统的性质就会改变,它不再只是一个私有目录,而更像一个可以持续被调用、补充、修正的个人基础设施。
LLM Brain 目前还不是 MindOS 那种更完整的人机协同系统,但我在 MCP 这一层的取向,明显受了它的影响。
还有一个很具体、很工程化的借鉴,是 Obsidian Web Clipper。在 LLM Brain 里,Web Clipper 不是一个边缘工具,而是 raw/articles/ 这条入口成立的前提。没有稳定的 markdown 化输入,后面的编译链路就没有干净的起点。
所以如果要给这个项目做一个准确的定位,我更愿意这样说,它借鉴了 Karpathy 对知识编译的基本模式,参考了 MindOS 对共享心智层的方向判断,再把这些东西落成了一套更克制、更本地、更文件系统优先的实现。
系统结构其实非常朴素,但边界很清楚
这个项目的代码目录并不复杂,核心都在 .llm/ 下面:
compile.py负责主编译流程compile_indexes.py负责索引页生成ask.py负责问答和结果回写mcp_server.py负责把知识库暴露给 Claude Desktop、Cursor 等客户端config.yaml管路径、模型和实体配置prompts/目录里现在有 12 个 prompt 模板state/目录负责持久化状态
对应的知识输出则落在 wiki/ 下的几个固定目录里:
wiki/summaries/wiki/concepts/wiki/companies/wiki/people/wiki/analyses/wiki/indexes/
再往前一层,是 raw/ 目录,负责存放文章、论文、访谈、报告等原始材料。wiki/SCHEMA.md 则把目录职责、卡片格式和状态文件含义写成了显式文档,而不是把这些约定散落在 prompt 和代码里。
这个结构的重点,不是“目录分得多漂亮”,而是它把知识库拆成了几个可以被 LLM 稳定维护的层级。原始输入、结构化中间层、实体层、索引层、问答回写层,各自职责清楚,系统才能持续演化,而不是越跑越乱。
关键不在总结,而在编译
如果只看表面,LLM Brain 很像一个会自动生成卡片的 Obsidian 项目。
但它真正做的事情不是“总结文章”,而是“把输入编译进一个持续可维护的知识结构”。
当前这一版里,一份新材料进入 raw/articles/ 之后,系统会把它拆进多种结果类型里。按照 README 和 schema 里的定义,核心产物包括:
- 结构化摘要
- 概念卡
- 公司档案
- 人物档案
- 索引页
问答阶段还会进一步产生:
- 分析卡片
- 对已有实体页的补充更新
这背后的区别非常大。
如果系统只生成摘要,那么每篇文章最终只对应一个结果文件,知识增长基本是线性的。可一旦它开始同时更新概念、公司、人物和索引层,知识库就不再是“加一篇文章”,而是“改写已有结构”。同一篇关于 HBM、SK 海力士、三星和 AI capex 的材料,会同时影响多个实体页和多个索引页,后续问答还可能把新的比较分析再写回 wiki/analyses/。
这就是我说它更像编译系统,而不是笔记工具的原因。
状态层决定了它是不是一个真正可持续运行的系统
很多看起来聪明的 LLM 工作流,最大的问题都不是 prompt,而是没有状态。
LLM Brain 里现在有几个状态文件,我认为它们比大部分生成结果还重要:
processed.json记录编译过的原始文件哈希entities.json维护实体和来源的引用关系aliases.json处理实体别名归并corrections.yaml保存用户修正
这里每一个文件都对应一个真实工程问题。
processed.json 解决的是增量编译。如果每次都从头跑一遍,知识库规模一大,维护成本就会失控。
aliases.json 解决的是实体漂移。真实世界里的对象名称并不稳定,SK Hynix、SK海力士、不同语言下的简称和别名,都会让知识库碎裂。如果没有 alias 层,实体页会越来越多,但知识不会越来越集中。
corrections.yaml 解决的是另一个更现实的问题,LLM 会犯错,而且这种错误如果没有回灌机制,就会反复出现。把人类修正显式写进状态层,再注入下一轮编译,比单纯手改某一页 markdown 更有长期价值。
所以我现在越来越确定,知识库系统的重点不是“模型写得多好”,而是“状态维护得够不够稳”。
问答回写,是这套系统里最关键的一步
如果说编译解决的是知识如何进入系统,那么问答回写解决的,就是知识如何继续积累。
Karpathy 在 LLM Wiki 里有一个我非常认同的判断,好的回答不应该死在聊天记录里。一次比较分析、一个新的连接、一个问出来的判断,只要有价值,就应该重新进入 wiki。
这件事我后来在 ask.py 里认真补上了。
当前的链路已经不只是 ask -> answer -> end。高质量问答结果可以被评分、分类,然后进入 wiki/analyses/,或者反过来补充到已有实体卡片里。这个变化看起来只是多了一个写文件动作,但系统性质其实变了。
从那一刻开始,问答不再只是消费知识,而开始生产知识。
这也是我觉得很多“AI 知识库”还没真正跨过去的一道坎。它们能回答问题,但不会因为这些问题本身变得更完整。LLM Brain 想解决的,恰恰是这一层。
当然,这里仍然有我还没完全想透的 tradeoff。比如,哪些回答应该自动入库,哪些应该提示确认,哪些只该留在 outputs/ 里。这个阈值现在已经有分流机制,但还远远谈不上完美。知识库如果要持续长大,最难的不是让它多写,而是让它少写错东西。
MCP 让它开始具备“基础设施”的味道
我后来加 mcp_server.py,目的很明确,我不希望这套知识系统只被 Obsidian 本地浏览。
当前这一层暴露的是 5 个工具:
read_wikisearch_wikilist_entitiesask_questionadd_note
这意味着 Claude Desktop、Cursor 这类客户端可以直接读知识库、搜知识库、列实体、发问、写入笔记,而不是每次重新从零理解上下文。
这个能力看起来并不夸张,但它让 LLM Brain 从“一个本地目录”开始往“一个个人知识接口层”靠近。也正是在这一步上,MindOS 给过我很直接的启发。共享知识层一旦建立起来,Agent 之间的上下文不再完全断裂,知识才有机会真正积累。
我为什么刻意保持技术栈克制
这个项目完全可以继续往更复杂的方向长。
比如向量检索、更复杂的图谱层、更重的前端、更多自动化 agent、更精细的关系边类型,全部都值得做。事实上,在 4 月 6 日那份对标 Karpathy 和 MindOS 的 gap analysis 里,我已经把不少下一步方向写出来了。
但在当前这个阶段,我反而更在意另一件事,系统是不是足够轻,足够透明,足够可维护。
现在这套实现的核心依然是本地文件系统、Python 脚本、Obsidian markdown、少量持久化 JSON/YAML 状态,以及 MCP 暴露出来的轻接口。它没有把知识锁进一个更重的服务,也没有让整个工作流依赖一套昂贵复杂的基础设施。
我喜欢这种克制,因为它迫使我把复杂度放在知识结构和维护逻辑里,而不是放在技术包装上。
为什么这件事值得继续做
如果只把 LLM Brain 看成一个工具,它当然还很早期。
图谱层怎么做得更可编程,回写边界怎么控制,实体页怎么避免越编越胖,类型化关系边怎么引入,分析卡和实体卡之间的更新策略怎么收敛,这些都还是后面的工作。
但它已经让我确认了一件事,个人知识库的下一步,不应该只是“更方便地记”,而应该是“更持续地编译”。
我现在越来越相信,LLM 真正适合长期停留的位置,不是在聊天框里临时显得聪明,而是在一个可维护的知识结构里,安静地做那些人类做起来很累、但又不得不做的整理、归并、更新和回写。
这件事看起来不像一个 flashy 的 AI 产品。
但它很可能比大多数 flashy 的 AI 产品更接近长期价值。
References And Acknowledgements
- Andrej Karpathy, LLM Wiki
关系:核心灵感来源。raw -> wiki -> schema的知识编译模式、问答回写和log.md / index.md这些关键思想,都直接帮助我定义了这类系统的基本形态。 - GeminiLight / MindOS
关系:对标与方向参考。它让我更明确地看到,多 Agent 共享知识层、通过 MCP 暴露能力,不只是实现细节,而是系统边界会发生变化的一步。 - Obsidian Web Clipper
关系:实际工作流依赖。LLM Brain 里raw/articles/这条输入链路,默认就建立在稳定的网页转 markdown 采集之上。